

APM – Cómo diagnosticar problemas periódicos
En este artículo indicamos cómo podemos identificar los distintos tipos de problemas periódicos y cómo debemos priorizar para solucionarlos.
Definición de problema periódico
Un problema periódico es aquel que ocurre de forma regular y está asociado a la hora del día y a la carga. La mayoría de los problemas que se ajustan a esta categoría muestran cierto tipo de recuperación antes de que ocurra el problema.
Esta definición de un problema periódico sugiere que estos problemas ocurren cuando la cantidad de tráfico excede la capacidad del servidor y la aplicación está sobrecargada. También se presentan problemas periódicos cuando la capacidad del servidor no se utiliza al máximo debido a problemas de configuración.
El sistema algunas veces, una vez que pasan estos problemas periódicos puede recuperarse.
Tipos de problema periódico
Las seis causas de los problemas periódicos son las siguientes:
- Sobrecarga: Ocurre cuando el tráfico satura el servidor de aplicaciones
- Infrautilización: Ocurre cuando el servidor no toma ventaja de su propio hardware
- Cuello de botella interno: Ocurre cuando un componente ha sido construido para gestionar un número limitado de peticiones
- Cuello de botella de backend: Aplica los tres primeros puntos a una base de datos o a un sistema externo al que hay que conectarse.
- Saturación de la red: Es el resultado de una capacidad de red insuficiente. En otras palabras la cantidad de datos que se transfiere por la red excede a su capacidad
- GC frecuente: Impacta al rendimiento cuando un objeto se borra demasiado frecuentemente, como por ejemplo una conexión a la base de datos.
Sobrecarga
Un servidor de aplicaciones sobrecargado es aquel que experimenta tanto tráfico que termina fallando en responder a un nivel aceptable. La carga sube y baja en el curso de diferentes ciclos de negocio, haciendo que los problemas se repitan periódicamente. Algunas aplicaciones por ejemplo, experimentan una carga alta cuando se procesan las nóminas de los empleados o cuando se realizan múltiples reuniones online muy largas.
Independientemente de la razón, se ha cometido un error de cálculo en cuanto al rendimiento de la aplicación y con la capacidad del hardware.
Relación ente los síntomas
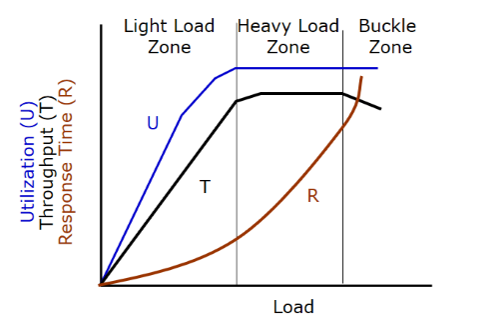
En el gráfico, T define el número de transacciones que se completan en un periodo de tiempo. U define la cantidad de recursos del servidor (CPU o memoria) que se consume. R es el tiempo que necesita el servidor para procesar la respuesta de la información solicitada.
Hay una relación funcional entre U, T y R bajo carga. En el gráfico se muestran las tres zonas de carga.
En la zona de Baja Carga, la capacidad del servidor, facilita una relación lineal entre el tiempo de respuesta y la carga. Cada nueva petición ralentiza el servidor por la misma cantidad.
En la zona de carga alta, las peticiones adicionales ralentizan el servidor de una forma exponencial. En ese momento la gráfica de la utilización (U) llega al 100% y el Througput (T) llega al máximo
En la zona de saturación, hay una relacion inversa entre as gráficas R y T. En ese momento la gráfica R supera a la T. Esta caída en T representa que el servidor está saturado y el decremento de la cantidad de datos procesados en un momento dado.
Métricas que identifican una sobrecarga
Un servidor sobrecargado muestra una alta concurrencia en el servlet controlador, ya que es el componente que recibe todas las llamadas de la aplicación. Además, el uso de CPU se incrementará ya que la cantidad de proceso que realiza el servidor es sustancialmente mayor que el habitual.
En este punto, se reconocerá el problema identificando que la carga de CPU es alta, los tiempos de respuesta crecen , el número de peticiones por segundo crece, disminuye el número de threads y el de conexiones disponibles.
Cuando es un problema de carga, el problema se redirige al administrador de sistemas o de red o al administrador del servidor de aplicaciones.
Infrautilización
Un sevidor infrautilizado es aquel que tiene más capacidad de hardware de la que está utilizando. Dos recursos que pueden impactar el rendimiento son a CPU y la memoria. A veces la configuración del servidor no está bien configurada de forma que la JVM no dispone de todo el potencial del hardware. Normalmente estas configuraciones se manejan por los ficheros de configuración de la JVM o del sistema operativo.
Otras áreas de preocupación son los threads o los pooles de conexión. Hay que tratar de encontrar el balance entre el número de threads disponibles en el pool y el hardware disponible para gestionar esos threads. Un pool que no sea suficientemente grande puede causar problemas bajo carga.
Métricas que identifican una infrautilización
Las métricas que identifican una infrautilización son muy diferentes a una sobrecarga de CPU. Una contención de threads normalmente en el servlet controlador pueden llevar a creer que hay una sobre carga, pero la CPU se mantiene a niveles normales con lo que se puede eliminar el problema de sobrecarga. Este nivel bajo de CPU indica que el servidro puede responder mejor a altas cargas de trabajo si se configura adecuadamente.
Se va a ver que bajan los threads disponibles y/o las conexiones disponibles a la base de datos hasta llegar en algún momento a no tener ninguno disponible.
Esto es un problema de configuración y hay que enviárselo al administrador del servidor de aplicaciones.
Cuello de botella interno
En un post anterior, se identificó un problema consistente en un escenario de código ineficiente. Un cuello de botella interno comparte algunas de las características con el código ineficiente, excepto que el problema sólo se presenta bajo carga.
Los cuellos de botella internos ocuren en componentes donde la contención puede ser una preocupación. La contención significa que los datos se deben bloquear o la lógica procesada por un único usuario a la vez. Java gestiona esto mediante la sincronización, una característica del lenguaje que indica a la JVM de permitir sólo una petición a la vez en ciertas partes del código. La palicación funciona perfectamente hasta que hay un alto número de peticiones al componente sincronizado.
Métricas que identifican un cuello de botella interno
Este problema se identifica al hacer un dump de threads, en el que se identificarán una serie de threads en estado de espera para el mismo método que llama a un método que estará sincronizado.
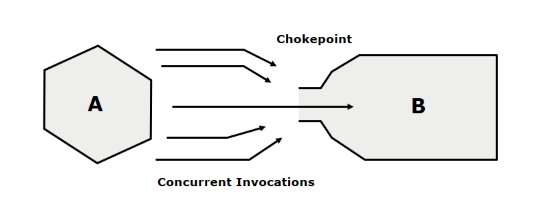
En cuanto a las métricas, se incrementará el tiempo de respuesta, se decrementará el uso de CPU y el número de threads disponibles y se identificará en el dump de threads que ese método que llama al método sincronizado está en espera.
Es un problema de código y hay que enviárselo al programador o al arquitecto que debe revisar que la sincronización se ajuste sólo a las líneas que lo necesiten
Cuello de botella de backend
Un cuello de botella de backend relacionado con carga del sistema puede ser el resultado de un servidor infradimensaionado o de un servidor de backend sobrecargado. Los cuellos de botella pueden venir también por sentencias SQL mal diseñadas o problemas de contención que se presentan con grandes cantidades de tráfico.
Se puede solucionar configurando mejor los servidores de bases de datos para que las bases de datos puedan utilizar toda la potencia del hardware y resolver los problemas de contención de forma que tener múltiples usuarios no cause atascos de tráfico mientras esperan por resultados.
Métricas que identifican un cuello de botella de backend
Las métricas que van a identificar el problema van a ser en un dump de threads, el método que llama a la base de datos se llamará múltiples veces y estará en espera, se verán tiempos de espera a la ejecución de las consultas a la base de datos altos y se disminuirá el número de threads disponibles.
Este tipo de problemas hay que enviarlo al administrador del backend para que revise la configuración y las consultas. Como es un problema periódico, normalmente con una configuración mejor del sistema backend se puede solucionar el problema,
Saturación de la red
Se genera porque la cantidad de datos que se transfieren a lo largo de la red excede la capacidad de la misma. Puede ocurrir cuando el router falla, o las páginas web no están optimizadas en tamaño.
Este problema hay que identificarlo monitorizando el tráfico de la red e identificando dónde se genera el problema. No es una monitorización de la aplicación, sino de los sistemas.
Este tipo de problemas hay que enviarlo a un administrador de sistemas para que revise el tráfico de red.
GC Frecuente
Al generarse mucho uso de memoria, se generan ejecuciones del GC, como el GC es un proceso sincronizado, se detiene el proceso mientras se ejecuta si se genera mucho movimiento de datos al límite de memoria, se ejecuta múltiples veces, generando que el sistema no funcione el máximo de capacidad, incrementando el uso de CPU.
Para identificarlo, se revisa el tiempo de ejecución del GC y el porcentaje de ejecución.
Es un problema de código y por tanto hay que redirigirlo al programador o al arquitecto.
Resumen
Con este artículo hemos finalizado esta serie de identificación de los problemas de rendimiento en las aplicaciones y cómo solucionarlos.
En BLMovil tenemos más de 15 años de experiencia en APM, con proyectos de monitorización de más de 1.500 servidores. Si necesitan identificar los problemas de rendimiento de sus aplicaciones no duden en contactarnos.
Tanto si estás buscando trabajar full time, como suplementar tus actuales ingresos con desarrollos adicionales a los que estás haciendo en tu actual trabajo, o quieres implicarte en el desarrollo de proyectos opensource y apoyar a la comunidad, rellena el formulario que hay a continuación y nos pondremos en contacto contigo para ver los proyectos en los que podemos colaborar.