

APM – Cómo diagnosticar problemas progresivos
En este artículo indicamos cómo podemos identificar los distintos tipos de problemas progresivos y cómo debemos priorizar para solucionarlos.
Un problema progresivo es uno que se degrada a lo largo del tiempo. El uso de los recursos, memoria y CPU se incrementa significativamente durante un problema progresivo, especialmente hacia el final del mismo. Hay que ser capaz de identificar los problemas que causan los problemas de rendimiento progresivos y los pasos que hay que tomar para resolver estos problemas.
Después de leer este artículo debes ser capaz de identificar los problemas progresivos y de priorizar los problemas progresivos basados en sus características.
Definición de problema progresivo
Un problema progresivo es aquel en el que el rendimiento se degrada a lo largo del tiempo, el rango de severidad es alto, el uso de la CPU y de la memoria se incrementa, el problema afecta normalmente a todas las funciones y el servidor puede llegar a bloquearse.
La solución que se suele tomar es planificar reinicios del sistema.
Un problema progresivo es una condición que degrada el uso de los recursos, memoria y CPU a lo largo del tiempo. Algunos problemas progresivos puen llevar a que el sistema termine cayendo en minutos, mientas que otros pueden tomar días hasta que se empiece a notar el problema. EL uso de los recursos se incrementa significativamente durante un problema progresivo, especialmente al final del mismo. Típicamente, estos problemas terminan causando que el sistema termine cayendo y se necesite un reinicio del sisteme.
Causas Principales de los problemas progresivos
Hay tres causas por as que puede ocurrir un problema progresivo:
- Bloqueo de recursos
- Una estructura de datos creciente
- Un bloqueo
Estos motivos están relacionados entre sí en la forma que las fugas terminan impactando al Garbage Collector, y las métricas y firmas de las mismas son idénticas.
La solución que se suele tomar es planificar reinicios del sistema.
Un problema progresivo es una condición que degrada el uso de los recursos, memoria y CPU a lo largo del tiempo. Algunos problemas progresivos puen llevar a que el sistema termine cayendo en minutos, mientas que otros pueden tomar días hasta que se empiece a notar el problema. EL uso de los recursos se incrementa significativamente durante un problema progresivo, especialmente al final del mismo. Típicamente, estos problemas terminan causando que el sistema termine cayendo y se necesite un reinicio del sisteme.
Garbage Collector
Ahora que se han identificado los potenciales problemas progresivos, aprenderemos a identificarlos por sus métricas. Mediante esta identificación, se podrán priorizar y asegurarse de que los problemas que perjudiquen más al negocio son resueltos antes.
Para comprender ciertos tipos de problemas progresivos, es útil explorar el Garbage Collector porque está impactado por los bloqueos de recursos, estructuras de datos crecientes y memory leaks.

Como cualquier otro recurso, la memoria es un recurso limitado. Para asegurarse de que la memoria tiene un uso eficiente, hay muchos lenguajes de programación que disponen de un garbage collector para determinar qué objetos ya no se referencian más y se pueden mover de la pila de la memoria.
El gráfico ilustra cómo se selecciona un objeto del Garbage Collector. El objeto en el medio ya no tiene referencias que apunten a él, lo que significa que no hay nda que tenga que ver con él y está en la memoria sin ninguna razón que lo justifique. El resto de objetos tienen referencias y están por tanto activos. La siguiente vez que se ejecute el Garbage Collector, limpiará todos los objetos sin referencias.
Normalmente los problemas progresivos se relacionan con el Garbage Collector. El Garbage Collector reclama memoria y determina qué objetos se están utilizando, y libera el espacio para ser utilizado por otros objetos.
Si queda poco espacio ara liberar, el Garbage Collector se tiene que ejecutar con más frecuencia para liberar la memoria necesaria para que el software siga funcionando. Cuanta menos memoria quede libre, más veces se va a ejecutar el Garbage Collector para liberar memoria y más uso de CPU que va a utilizar este proceso, que además es un proceso sincronizado que hace que el resto de procesos se detengan hasta que termine el proceso de Garbage Collector.
Bloqueo de recursos
La fuga de recursos suele ocurrir en componentes que están realizando procesos de E/S o conectándose a un back end. Si la conexión o el socket se abre pero no se cierra, se gastan recursos de memoria. Las conexiones de la base de datos se liberan por el Garbage Collector después de un tiempo de timeout predeterminado. Los sockets, sin embargo, no se liberan si no se cierran.
La mayoría de los sistemas de Garbage Collection tienen un mecanismo de limpieza que se lanza cuando la memoria empieza a acabarse. Según se va ocupando la memoria por las fugas de recursos, la aplicación empieza a ir lenta debido a dos razones, la falta de memoria, y la ejecución frecuente del proceso de Garbage Collector.
Los recursos que generalmente causan estos problemas son:
- Conexiones a sistemas back end
- E/S de archivos
- Sockets
- Threads
Bloque de Recursos: Threads
El bloqueo de los recursos ocurre cuando dos threads se bloquean el uno al otro. Esto no bloquea otras peticiones. El problema de degradación, se va dando cuando otros usuarios ejecutan el mismo proceso, y el número de threads bloqueados va aumentando continuamente.
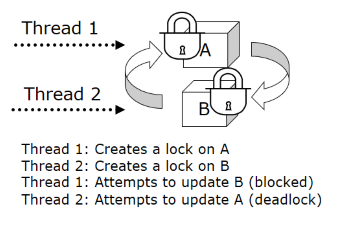
Los deadlocks ocurren debido a problemas de programación. Los componentes de JAva se pueden sincronizar, lo que significa que sólo un thread puede utilizar el componente a la vez. Cuando un thread usa un componente sincronizado, lo bloquea de forma que ningún otro puede interferir.
El diagrama muestra como ocurre un deadlock con los componentes sincronizados A y B. El thread 1 bloquea el componente A y el thread 2 bloquea el componente B. Con el componente A bloqueado, el thread 1 espera a que el thread 2 libere su bloqueo con el componente B. Al mismo tiempo, el thred 2 está esperando a que el bloqueo en el componente A se libere. Los threads están interbloqueados.
En este artículo, se describen dos tipos de interbloqueo. El interbloqueo del gráfico es un interbloqueo no bloqueante y ni es un interbloqeo serio. Los interbloqueos no bloqueantes afectan únicamente a dos hilos a la vez. El objeto o pieza del código que está bloqueado no se usa por todo el sistema por lo que el interbloqueo no es tan severo. Si embargo por cada llamada al objeto en particular se gastan dos threads más y el problema empeora.
Las métricas que identifican el problema son las siguientes:
- La métrica de threads disponibles va disminuyendo de forma continua hasta eventualmente llegar a cero
- El tiempo medio de respuesta se va incrementando cada vez más
- El uso de CPU termina cayendo a cero, ya que no se puede ejecutar ningún trabajo
- Si se realiza un dump de threads, se identifica que todos están detenidos en los mismos métodos
Se puede sospechar que hay interbloqueos, cuando la métrica de hilos disponibles tiende a cero, indicando que no se liberan los hilos. Como no hay threads disponibles, la aplicación no puede realizar ningún trabajo. Este problema de servidor de aplicaciones bloqueado, hace que el uso de CPU sea anormalmente bajo.
Además de estas métricas, al realizar un dump de thread, se verán los threads bloqueados y el método o métodos que están generando dicho bloqueo.
Memory Leaks: Colecciones
Como los leaks de recursos, las estructuras de datos crecientes son una forma de leak que usan progresivamente más memoria. Esto ocuure cuando se están añadiendo objetos a la estructura, pero no se eliminan. Esto por ejemplo puede ser un objeto de sesión que no se elimina ni expira debido a un código pobremente escrito.
Para identificar este tipo de problemas, lo que se puede realizar es un memory dump, donde se identifiquen los objetos que están consumiendo más memoria. Se puede además con ciertas herramientas, realizarvarios memory dumps a lo largo del tiempo, e identificar las variables que van creciendo a lo largo del tiempo y no liberan memoria.
Memory Leaks: No colecciones
Los memory leaks también ocurren cuando se mantienen referencias a objetos que ya no se utilizan. Estos objetos deberían eliminarse con el Garbage Collection si la referencia ya o existe. Si un objeto mantiene una referencia a él, no se marca para limpiar. Este memory leak resulta en un número creciente de instancias del objeto. Como en el caso anterior, con un Memory Dump, se pueden ver las instancias de un objeto en memoria e identificar si van creciendo con el tiempo.
Métricas que identifican los Memory Leaks
La mayoría de las métricas crecen mientras crece el leak. El uso de CPU se incrementa hasta llegar al 100% cuando el servidor va a caer, el tiempo de Garbage Collection, se incrementa al 100%, las métricas fluctuan según fluctúa el Garbage Collection.
Mientras el Garbage Collector intenta hacer lo que puede para mantener memoria libre, se va incrementando su uso de recursos, principalmente de la CPU, hasta que el problema e hace inmanejable, la CPU llega al 100% y se obtiene un mensaje de Out of memory.
Relación entre Garbage Collection y CPU
Cuando se ejecuta el Garbage Collection, todo el procesamiento se detiene durante un tiempo determinado, desde una fracción de segundo a varios segundos. Además, la CPU se dispara debido a las necesidades de procesamiento del Garbage Collector. Si la CPU se dispara en intervalos cada vez más cortos y y no se recupera mientras fluctúa el Garbage Collector, tienes la prueba de que es un problema relacionado con la memoria.

Objetos de sesión que no expiran
Las sesiones inactivas que no expiran son otro de los ejemplos de un memory leak. Observando el número de sesiones activas que existen y las que expiran, se puede ver si la expiración es incompleta, dejando objetos en memoria que ya no son necesarios.
Resolución de problemas de Memory Leak
Los problemas de Memory Leak, siempre se deben a problemas de mala codificación y se deben redirigir a un programador o a un arquitecto.
Los problemas normalmente vienen de dos posibles escenarios:
- Una estructura de datos con objetos que se añaden pero no se eliminan
- Una conexión o un socket que no se cierra convenientemente.
Si necesita más información sobre APM, o configuración de monitorización de sus aplicaciones no dude en contactar con nosotros en nuestro correo.
Tenemos más de 10 años de experiencia en monitoreo de aplicaciones en implantaciones de más de 10.000 servidores de aplicaciones en diferentes países.
Tanto si estás buscando trabajar full time, como suplementar tus actuales ingresos con desarrollos adicionales a los que estás haciendo en tu actual trabajo, o quieres implicarte en el desarrollo de proyectos opensource y apoyar a la comunidad, rellena el formulario que hay a continuación y nos pondremos en contacto contigo para ver los proyectos en los que podemos colaborar.