
APM – Cómo diagnosticar problemas repentinos
En este artículo indicamos cómo podemos identificar los distintos tipos de problemas repentinos y cómo debemos priorizar para solucionarlos.
Definición de problema repentino
Un problema repentino es:
- Instantáneo, no es lineal ni progresivo
- Ocurre sin aviso, funciona bien un minuto y deja de hacerlo al siguiente
- Es recurrente, pero en horarios diferentes
El servidor de aplicaciones puede llegara colgarse, comenzar a generar errores o actuar caóticamente y el problema normalmente afecta a todas las funcionalidades
Interbloqueo activo
- Interbloqueo activo
- Reintentos sin fin
- Un cerdo en la pitón
- Un Backend repentinamente lento
- Punto muerto
Reintentos sin fin
Pueden estar causados por componentes que hagan llamadas continuas a sistemas no disponibles, es uno de los problemas más comunes de que el sistema se cuelgue o deje de responder.
Suele ocurrir cuando el componente no puede diferenciar entre una respuesta exitosa o un fallo y para solucionarla requiere una monitorización del back-end
Las métricas que definen este problema son las siguientes:
- El tiempo de respuesta para el método que llama el sistema se incrementa
- El número de threads disponibles llega a cero si el problema es muy grave
- En un dump de threads, se ve que los threads están detenidos en el método que causa el problema
- El uso de CPU tiende a cero, que que la máquina no puede realizar trabajo al estar a la espera de respuesta
El problema hay que redirigirlo al programador y/o arquitecto por si es un problema de desarrollo de no identificar si la respuesta no ha llegado de forma correca o no, y también hay que redirigirla al administrador del sistema backend para que lo compruebe
El cerdo en la pitón
Este problema viene como el nombre dice, por intentar hacer pasar algo grande por un canal pequeño. Por ejemplo, consumir toda la memoria disponible por conjuntos de datos enormes, normalmente se recibe un error de Out of Memory.
Las métricas que definen este problema son las siguientes:
- Mayor tiempo de respuesta de la media en el método que llama al objeto
- La memoria utilizada tiende a ser igual a la memoria disponible
- El número de respuestas por intervalo disminuye
- Y en un dump de memoria, se vería el uso de memoria de ese objeto.
Para solucionar este problema que siempre es de programación, hay que enviárselo al programador o al arquitecto.
Backend repentinamente lento
Hay múltiples causas para un bajo rendimiento de la base de datos, como:
- Saturación de la red
- Bloqueo por otro usuario
- Recursos de base de datos inadecuada
- Boqueo por otro proceso
- Mal diseño de la Base de Datos o del Esquema de Datos
Hay que mantener actualizadas las estadísticas y monitorizar cada instalación de base de datos
Las métricas que identifican este problema son las siguientes:
- Tiempos de respuesta elevados en las peticiones a la base de datos
- El número de hilos decrece
- En un dump de threads se identifican los métodos que llaman a las consultas que terminan generando los problemas
Este tipo de problemas hay que redirecccionarlo al responsable del sistema backend
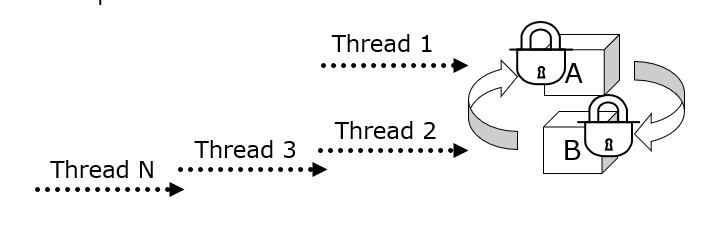
Punto Muerto
El punto muerto ocurre cuando dos procesos bloqueados se esperan el uno al otro para levantar el bloqueo. El punto muerto es un punto único de fallo, bloqueando otras peticiones

Las métricas que identifican este problema son las siguientes:
- En un dump de threads, se ve que el número de threads bloqueados se va incrementando paulativamente y siempre teniendo como origen la primera de las funcionaes.
- Las respuestas por intervalo se decrementan
- El número de threads, se decrementa hasta llegar a cero
- El uso de CPU va decayendo, ya que todos los procesos están esperando a que uno se libere y por tanto no se puede ejecutar nada.
Este es siempre un problema de código y por tanto hay que enviarlo al programador o al arquitecto.
Si necesita más información sobre APM, o configuración de monitorización de sus aplicaciones no dude en contactar con nosotros en nuestro correo.
Tenemos más de 10 años de experiencia en monitoreo de aplicaciones en implantaciones de más de 10.000 servidores de aplicaciones en diferentes países.
Tanto si estás buscando trabajar full time, como suplementar tus actuales ingresos con desarrollos adicionales a los que estás haciendo en tu actual trabajo, o quieres implicarte en el desarrollo de proyectos opensource y apoyar a la comunidad, rellena el formulario que hay a continuación y nos pondremos en contacto contigo para ver los proyectos en los que podemos colaborar.